データデザイナーでピボットタスク
重要 - 画像/情報は四半期ごとのリリースで更新されます!
四半期ごとのリリースにて、最新の機能・情報を反映し、画像を含めた情報は更新されます。
この記事では、管理者にピボットタスクを使用してデータデザイナーでデータを単純化された実用的なデータセットに変換する方法について解説します。
ピボット機能:ピボットは、出力時に1つの列の一意の値を複数の列に変換することにより、テーブルで使用可能なデータを変換します。
概要
データセットでは、ピボットタスクは1つのテーブル列で使用可能なデータを一度に複数の列に変換します。ピボットタスクはテーブル列のすべてのデータ値に対して列を作成します。これにより、データ要約プロセスが強化され、データに対する洞察が改善します。
ピボット機能を使用するためには、[管理] > [データ デザイナー] > [データセットを開く] の順にに移動し、[オプション] をクリックして、[ピボット] をクリックします。
ピボットタスクを使用すると次のようなメリットがあります。
- データを簡単に要約
- データ分析をより簡単に
- データパターンの発見を支援
- より迅速な意思決定を支援
ピボットタスクの目的
ピボットタスクの目的は、テラバイト (TB) 単位の大容量生データを組織の必要に応じて有用な情報に要約したピボットテーブルを作成することにあります。より迅速な意思決定を支援
カスタマーサクセスディレクター (CSD) がCTAタイプのパターンから、どのCSMがどのCTAタイプに関心があるかを知りたいというシナリオを考えてみましょう。
管理者はピボットタスクを使って、CTAタイプ名列 (単一の列) の記録 (値) を、CSM名でグループ化された個々のCTAタイプ名の複数の列に直接変換することができます。
次の表では、CSM名とCTAタイプ名の記録が2つの列に表示されます。このようなシナリオでは、どのCTAタイプ名の数が最も多いか、どの CSMがどのCTAタイプに関心があるかなどを手動で計算するのは困難になります。
|
CSM名 |
CTAタイプ名 |
|---|---|
|
Avneesh S |
アクティビティ |
|
Avneesh S |
拡張 |
|
Rakesh Kondam |
ライフサイクル |
|
Rakesh Kondam |
目的 |
|
Sandeep Dugar |
ライフサイクル |
|
Sandeep Dugar |
ライフサイクル |
|
Sandeep Dugar |
拡張 |
|
Sandeep Dugar |
拡張 |
|
Sandeep Dugar |
ライフサイクル |
|
Sandeep Dugar |
ライフサイクル |
上記のビジネスシナリオは、管理者がすべてのCTAタイプ名 (各データ値) の列を作成するピボットタスクを実行するのに役立ちます。このシナリオでは、次のフィールドが使用されます。
- CTAタイプ名:
- 拡張
- リスク
- アクティビティ
- ライフサイクル
- 目的
- CSM名
CSM名とCTAタイプ名という2つの列を持つデータデザイナーにデータセットが既にあるとします。このユースケースを実現するためには、CTAタイプ名フィールドをピボットし、CSM名フィールドにグループ化クローズを適用する必要があります。データセットのプレビューが実行されると、次の表が表示されます。
|
CSM名 |
拡張CTA |
リスクCTA |
アクティビティCTA |
ライフサイクルCTA |
目的CTA |
|---|---|---|---|---|---|
|
Avneesh S |
2 |
2 |
2 |
2 |
2 |
|
Rakesh Kondam |
2 |
2 |
2 |
2 |
2 |
|
Sandeep Dugar |
6 |
6 |
6 |
6 |
6 |
上記の出力表から、カスタマーサクセスディレクターは、どのCTAタイプ名が最も多く、どのCSMがどのCTAタイプに関心があるかを簡単に理解することができます。
データデザイナーのピボットタスク
このセクションでは、単一の列で使用可能なデータを複数の列に変換するピボットタスクをデータデザイナーで作成する方法について解説します。
データセットを作成する
データセットを作成するには:
- [管理] > [データデザイナー]に移動します。既存のデザイン一覧を閲覧することができます。
メモ:詳細情報については、その他のリソースセクションのデザインリストページとオプション記事をご参照ください。 - 新しいデザインをクリックします。

- [デザイン名]テキストボックスに好みのデザイン名を入力しますす。
- デザイン一覧ページですでにフォルダを作成している場合、[フォルダーの選択]ドロップダウンリストから、このデザインを追加するフォルダーを選択します。デフォルトでは、デザインは未分類フォルダーに保存されます。
- 説明テキストボックスに、選択した説明を入力します(オプション)。
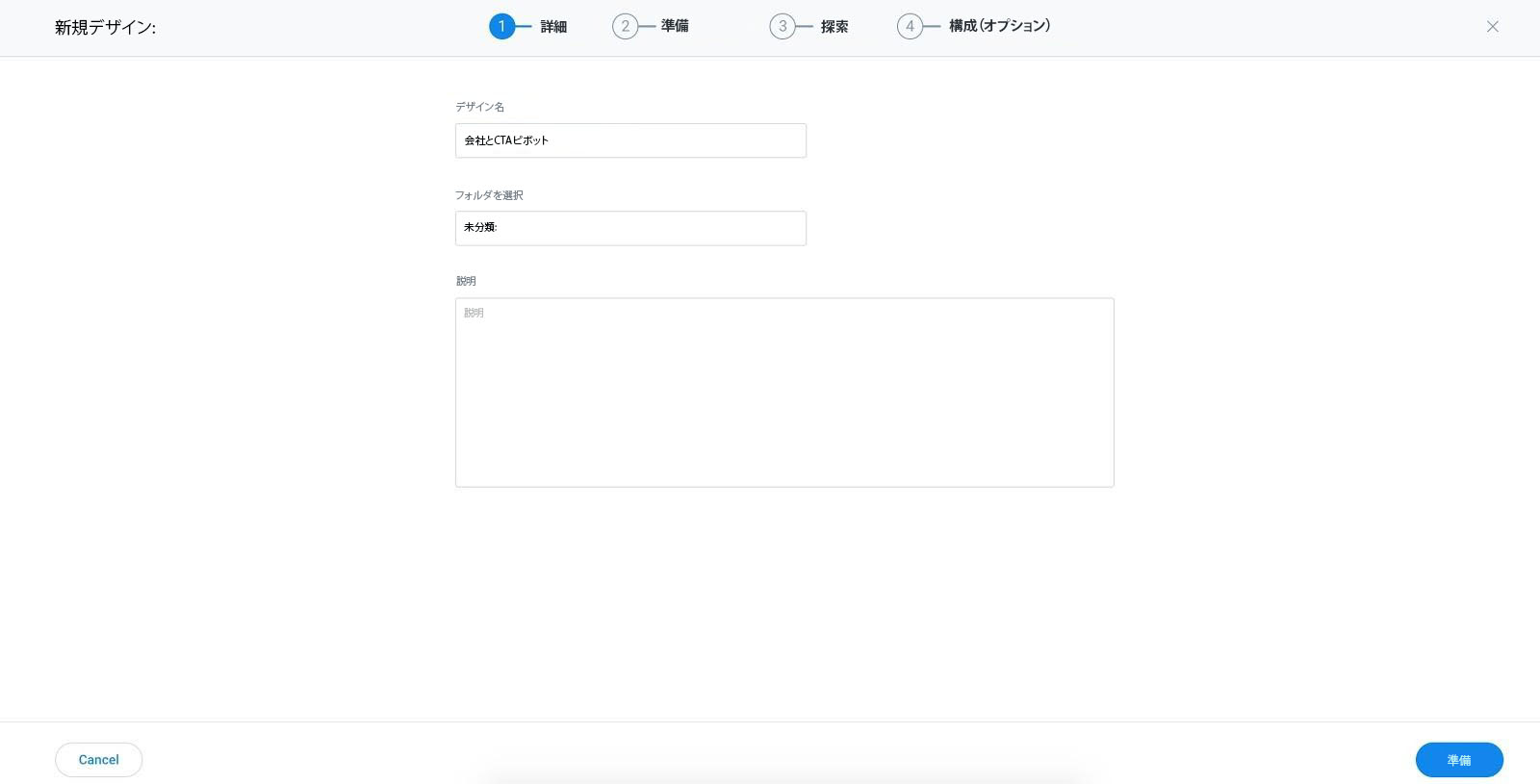
- 画面の右下隅にある準備をクリックしてデザインを保存し、準備タブに移動します。
- データソースロップダウンメニューから、マトリックスデータソースを選択します。選択されたデータソースの下にあるすべてのオブジェクトが表示されます。
- オブジェクト一覧からカンパニーオブジェクトをデータ準備画面にドラッグ アンドドロップします。
- データセットに追加したい必須フィールドを選択します。この例では、次のフィールドが追加されます。
- カンパニー名
- CSM名
- [選択] をクリックします。
- [保存] をクリックします。
同様に、次のフィールドを使用して、Salesforce接続データソース > コールツアクションオブジェクトに別のデータセットを作成します:
- CTAタイプ名
- アカウント名
データセットを作成する方法については、追加リソースセクションにある
データデザイナーでのデータセットの作成記事を参照してください。
マージタスクを作成
データセットは次の方法でマージされます:
- マージするデータセットの[オプション]をクリックします。ここでは、コールツアクションオブジェクトが選択されています。
- 統合をクリックします。
- 必要なデータセットを選択します。ここでは、カンパニーオブジェクトが選択されています。

データセットを結合すると、データセット名が[マージ]の新しいウィンドウが表示され、[詳細と概要]、[結合]、[フィールド]、および[フィルター]タブが表示されます。
データセットをマージする方法については、追加リソースセクションにあるデータデザイナーでのデータセットの作成記事を参照してください。
ピボットタスクを作成
ピボットタスクを作成するには:
- ピボットするデータセットの[オプション]をクリックし、次に[ピボット]をクリックします。[「マージ」にピボット] というデータセット名の新しいウィンドウが表示され、[詳細と概要]、[ピボット]、[フィールド]、および[フィルター]タブが表示されます。
メモ: データセットごとに構成できるピボットは1つのみです。
- [ピボットするフィールドを選択]ドロップダウンリストから、[CTAタイプ名]フィールドを選択します。
- [+ 列を追加]をクリックして、単一のデータ値ごとにピボットフィールドクライテリアを定義します。この例では、演算子をEqualsに設定し、CTAタイプ名を入力します。
- [出力列ラベル]テキストボックスに好みのデザイン名を入力しますす。
CTAタイプ名のすべての記録に対して、ステップ3と4を実行します。
- 「フィールド」タブに移動します。
- グループ化したい必須フィールドを選択します。この例では、CSM名フィールドのチェックボックスとグループ化チェックボックスを選択します。
- [保存] をクリックします。
- プレビューをクリックします。
従って、この例ではCSM名に基づいてすべてのCTAタイプ名を要約するピボットテーブルが作成されます。カスタマーサクセスディレクターは、どのCTAタイプ名が最も多く、どのCSMがどのCTAタイプに関心があるかを簡単に理解することができます。
列の配置は、出力によって異なる場合があります。列を並べ替えるためには、列名をドラッグして必要な位置にドロップします。
その他のリソース
- デザイン一覧ページとおよびオプションの詳細については、デザインリストページとオプション記事を参照してください。
- データセットを作成する方法の詳細な手順については、データデザイナーでのデータセットの作成 記事を参照してください。
- [準備]タブの機能の詳細については、データデザイナーでの準備の詳細 記事を参照してください。
- [探索]タブの機能の詳細については、データデザイナーで詳細を検索記事を参照してください。
- データデザイナーでよくある質問の詳細については、データデザイナー FAQs記事を参照してください。