データデザイナーでの準備の詳細
重要 - 画像/情報は四半期ごとのリリースで更新されます!
四半期ごとのリリースにて、最新の機能・情報を反映し、画像を含めた情報は更新されます。
この記事では、[準備]タブの機能について解説し、探索プロセス用のデータセットを準備する際にそれらを利用する方法についても焦点を当てています。
概要
準備ステップでは、2つの異なるオブジェクトを変換、マージ、結合してデータセットを作成することができます。このドキュメントでは、2つの異なるオブジェクトに対して少なくとも2つのデータセットを作成していることを前提として、[準備]タブの機能について解説します。データセットを作成する方法の詳細な情報については、データデザイナーでのデータセットの作成 記事を参照してください。
データセットの準備中に、次の機能を使用することができます。
データデザイナーの[準備]タブにアクセスするには、[管理] > [データデザイナー]に移動し、編集する既存のデザインを開きます (または) [新規デザイン]をクリックして新しいデザインを作成し、[詳細]に入力して[準備]タブに移動します。
データセットの編集
データセットを編集するには、[編集]アイコン (または)[オプション]をクリックし、次に[編集]をクリックしてデータセットを編集します。[詳細と概要]、[フィールド]、および[フィルター]タブが表示されるページに移動します。
詳細と概要
詳細と概要タブから次のオプションを閲覧することができます:
- オブジェクト名:特定のデータセットが構築されているオブジェクトのオリジナルの名前を表示します。
- データソース名:データソース名を表示します。
- 出力データセット名データセット名を編集する場合は、[出力データセット名]テキストボックスに「データセット名」と入力します。
- 説明: 必要に応じてデータセットの説明を入力します。
- フィールドとフィルター:データセット内のフィールド (存在する場合はグループ化を含む) とフィルターの一覧を表示することができます。
フィールド
フィールドタブから次のオプションを閲覧することができます:
- 検索フィールド: [検索フィールド]テキストボックスに、検索したいフィールド名を入力します。検索操作はデータセットで利用可能なフィールドで行われます。
メモ:ユーザがフィールド名を入力すると、検索機能はベースオブジェクトからフィールドを取得します。ルックアップオブジェクトの検索をさらに拡張するには、検索を実行する前にルックアップオブジェクトを展開してください。 - フィールドの追加:[フィールドの追加]をクリックして、データセットに追加する必須フィールドを選択し、次に[選択]をクリックします。
- グループ化:データセット内のデータを細分化するために、グループ化に必要なフィールドを選択することができます。グループ化するフィールドを選択すると、データセット内の他の全てのフィールドが集約されます。
- グループ化を選択すると、カスタム会計年度を日付および日時フィールドに適用できます。
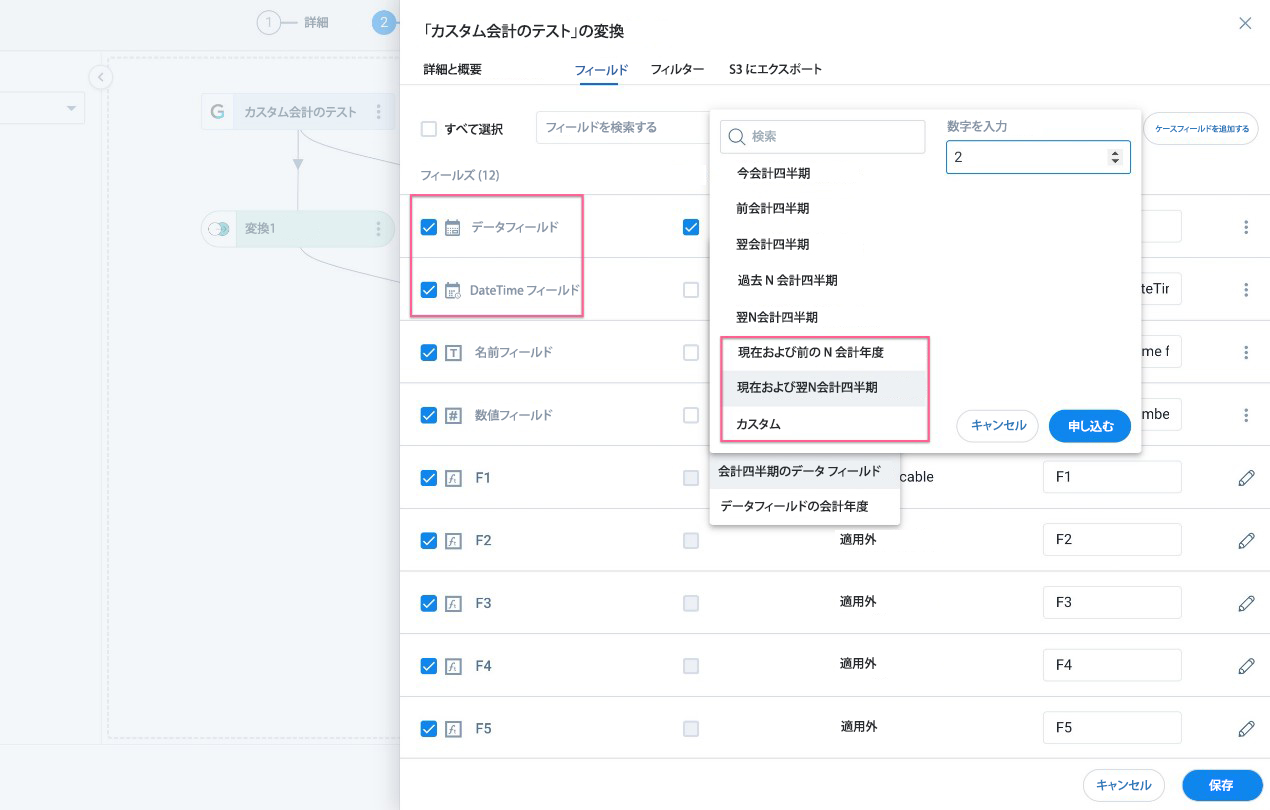
カスタム会計年度を構成する方法の詳細については、アプリケーション設定の記事を参照してください。
- 集約:[集計]ドロップダウンリストから必要な集計タイプを選択することができます。
- 表示名:デフォルトでは、[表示名]テキストボックスに[フィールド名]が表示されますが、必要に応じて変更することができます。表示名はデータセット/レポートに表示されます。
- 設定:
- 数値データタイプフィールドの場合、小数点以下の桁数を設定することができます。設定する小数点以下の桁数を入力するには、設定アイコンをクリックします
- 設定したいSalesforceピックリスト/マルチピックリストフィールドがすでにデータセットに追加されている場合:
- 右隅の設定アイコンをクリックします。
- [選択リストに変換]トグル ボタンを有効にします
- MDAへのマップドロップダウンリストから必要なドロップダウンリストを選択します。
メモ:
- SalesforceピックリストをGainsightのドロップダウンリストにマッピングする前に、Gainsightで同等のドロップダウンリストを作成済みである必要があります。ドロップダウンリストや複数選択ドロップダウンリストの作成方法の詳細については、Dropdown List and Multi Select Dropdown List記事を参照してください。
- Gainsightで同等のMDAドロップダウンを作成しないまま、必要な Salesforceピックリストにマッピングした場合は、値はnullとして表示されます。
- セットアップが完了すると、ユーザーはGainsightのフィルターとグローバル フィルターでピックリストを表示することができます。
- ピックリストのデータタイプを変更するには:
- [設定]をクリックし、[フィールドの複製]を選択します。ピックリストの文字列データタイプが表示されます。
- 削除:[削除] アイコンをクリックして、データセットからフィールドを削除します。
メモ:フィールドからデータセット (データスペース) を削除しようとすると、依存関係を知らせる通知がデータデザイナーに表示されます。これにより、データスペースですでに使用されているフィールドを誤って削除することを防止します。 - Save:[保存]をクリックして、データセットに加えた変更を保存します。
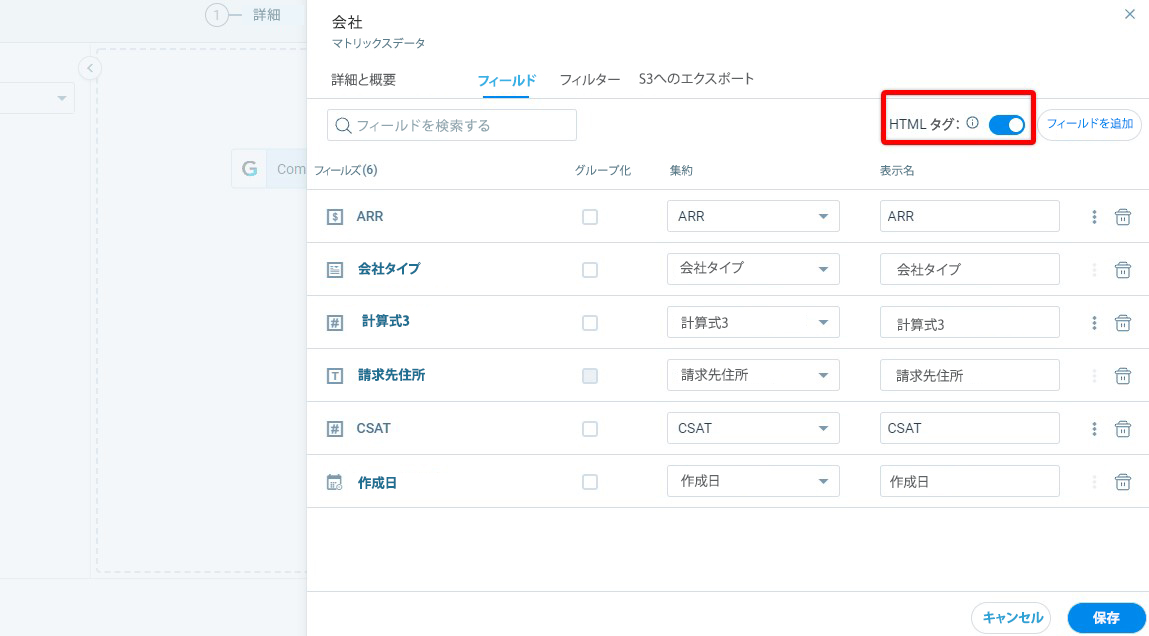
- HTMLタグ:HTMLタグは、リッチテキストフィールドを自動的に検出します。HTML タグスイッチはデフォルトでオンになっています。
メモ:HTMLタグは、S3へのエクスポートと単一データの一貫性の維持に寄与します。
カスケード追加
カスケード追加機能を使うと、フィールドをデータセットに追加することができます。その後、このフィールドはそのデザインの全てのデータセット (エンド タスク) に自動的に追加されます。
メモ:
- カスケード追加機能を使って追加された測定タイプフィールドのデフォルトの集計は合計です。フィールドが追加されたら、要件に基づいて集計を変更することができます。
- カスケード追加機能を使って追加されたディメンションタイプフィールドのデフォルトの集計はカウントです。フィールドが追加されたら、要件に基づいて集計を変更することができます。
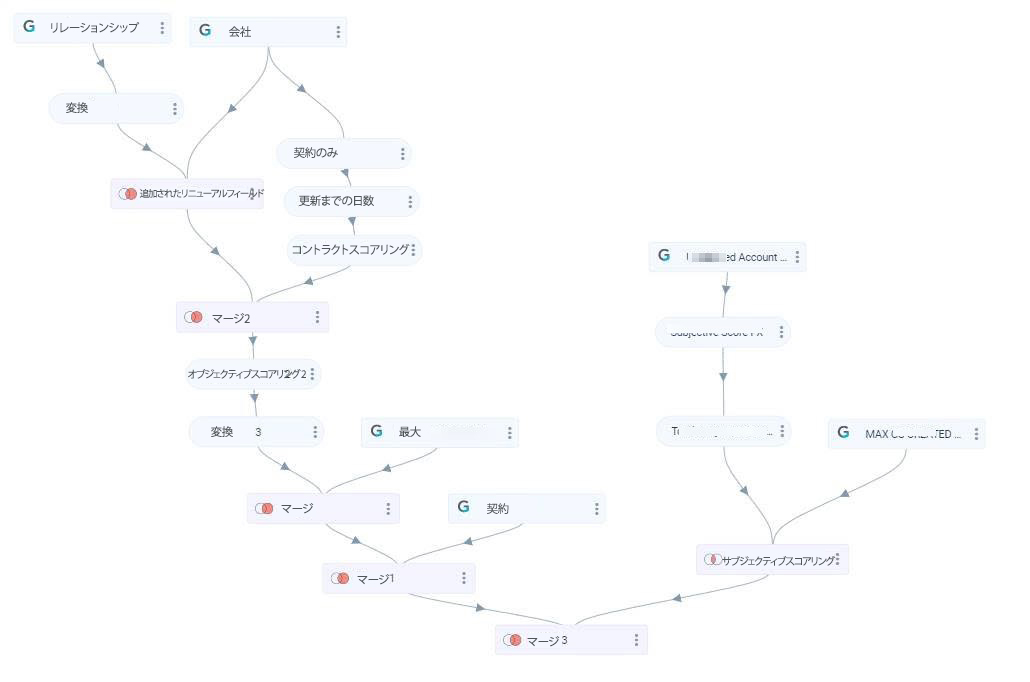
次の図に示すようなデザインがあり、新しいフィールドをエンドタスクに追加するとします。最初から個別に各タスクに新しいフィールドを追加するのではなく、カスケード追加機能を使うと、そのフィールドを親データセットに追加することにより、一度にすべてのタスクに新しいフィールドを追加することができます。
カスケード追加を実行するには:
- フィールドを追加するをクリックします。
- 必要なフィールドを選択します。
- [選択] をクリックします。
- [保存] をクリックします。[新しく追加されたフィールド]ウィンドウが表示されます。
メモ:このウィンドウに新しいフィールドの一覧が表示されます。 - [はい追加]をクリックして、選択した新しいフィールドをエンドタスクに追加します。
カスケード削除
カスケード削除を使うと、フィールドをデータセットから削除することができます。その後、このフィールドはそのデザインの全てのデータセットから自動的に削除されます。
デザインがデータスペースの場合、そして最後のデータセットからフィールドを削除しようとすると、Gainsightの他の機能間で依存関係を確認するための通知が表示されます。
カスケード削除を実行するには (デザインがデータセットの場合):
- 「削除」アイコンをクリックします。
- [他のタスクで使用されているフィールド]ダイアログが表示されます。
- [はい削除]をクリックして、後続のデータセットからフィールドを削除します。
- [保存] をクリックします。
カスケード削除を実行するには (デザインがデータスペースの場合):
- 「削除」アイコンをクリックします。
- [他のタスクで使用されているフィールド]ダイアログが表示されます。
- [とにかくフィールドを削除]をクリックして、後続のデータセットからフィールドを削除します (または) [依存関係を確認]をクリックして、そのフィールドのGainsightの他の機能との依存関係を表示します。
- 前の手順で[依存関係のチェック]を選択した場合は、依存関係の一覧を確認した後、[はい削除]または[削除しない]をクリックします。
- [保存] をクリックします。
フィルター
フィルタを適用するには:
- [フィルター] タブに移動します。
- フィルタを追加をクリックします。
- フィルタリングするフィールドを選択します。
- 演算子を選択し、[値]テキストボックスにデータを入力します。
メモ:
- [値]テキストボックスの横にある[+]アイコンをクリックして、さらにフィルターを追加しすることもできます。
- フィルタを削除するには、xアイコンをクリックします。
- 高度なロジックテキストボックスに必要な式を入力して、(A OR B) AND Cなどの高度なフィルタを追加することができます。
- [保存] をクリックします。
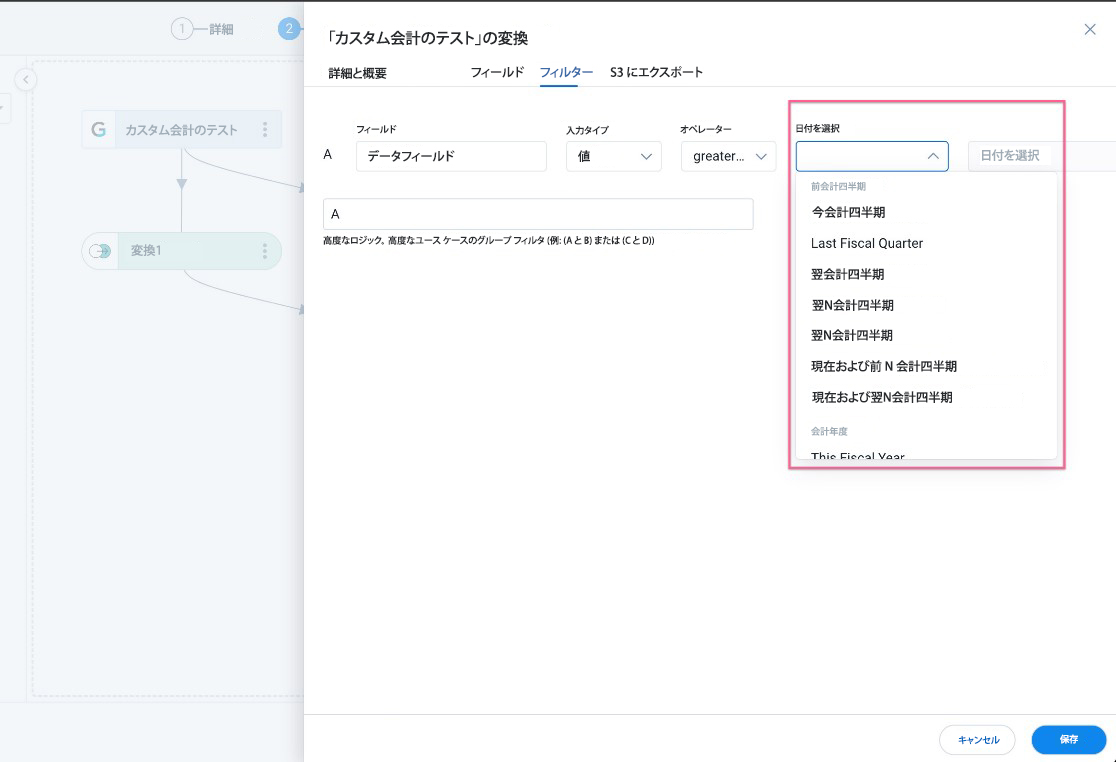
カスタム会計期間フィルター
カスタム会計期間フィルターは、日付および日時フィールドに適用できます。 フィルタを適用するには:
- [フィルター] タブに移動します。
- [フィルターを追加] をクリックします。
- フィルタリングする日付または日時フィールドを選択します。
- [入力タイプ] ドロップダウンから [値] を選択します。
- [演算子] ドロップダウンから、演算子を選択します。
- [日付の選択] ドロップダウンから、会計四半期を選択します。
- [値] フィールドに値を入力します。
- [保存] をクリックします。
マッピング
データデザイナーは Gainsightデータ管理に存在するマッピング情報を自動インポートします。マッピングは、カンパニー名などのコアフィールドを識別するためにレポート、ルール、JOなどのGainsightの他の機能によって使用され、特別に処理します。(ハイパーリンク、フィルターの自動提案)。
マッピングは、Gainsightアプリケーションがカンパニー名、関係名、ユーザー名、CTA、およびタイムラインサブジェクトなどの特別なフィールドをGainsight全体で識別するために使われるメカニズムです。
重要:名前フィールドのマッピングをサポートするには、対応するIDフィールドも追加し、それをデータ準備の最後のステップに持って行く必要があります。
マッピング機能を働かせる方法については、次の表を参照してください。
|
オブジェクト |
マッピングが必要なフィールド |
最後のタスクまで繰り越す必須フィールド |
|---|---|---|
|
アカウント |
アカウント名 |
アカウントID |
|
関係 |
名前 |
GSID |
|
企業 |
名前 |
GSID |
|
ユーザー |
名前 |
GSID |
データデザイナーからカンパニーオブジェクトおよびデータスペースで作成されたレポートで、カンパニー名にグローバルフィルターを適用することができます。
データスペースで作成されたレポートにハイパーリンクを表示することができます。例えば、レポートのカンパニー名と関係名の記録をハイパーリンクとして表示したり、レポートフィルターで自動提案を表示したりすることができます。
変換
変換を使うと、データセットに追加されたフィールドに数式フィールドとケース EXPRESSIONを適用することができます。
データセットに変換を適用するには、変換を適用するデータセットで[オプション]をクリックし、次に[変換]をクリックします。データセット名が「変換」の新しいウィンドウが表示され、[詳細と概要]、[フィールド]、および[フィルター]タブが表示されます。
フィールド
データセットに変換を適用した後、変換されたデータセットに追加されたフィールドで数式フィールドとケースフィールドを作成することができます。
データデザイナーの準備の詳細の数式フィールドとケースフィールドは、バイオニックルールの数式フィールドとケースフィールドとして機能します。数式フィールドとケースフィールドの作成方法の詳細については、 ケース フィールド (近日公開予定) 記事を参照してください。
[変換] > [フィールド]タブの他のすべてのオプションは、フィールド > データセットの編集 および フィールド > マージのオプションと同じように機能します。
数式フィールドを追加する
数式フィールドを作成するには:
- 「数式フィールドを追加」をクリックします。
- [ラベル]テキストボックスに数式フィールド名を入力します。
- 必要なデータタイプ (文字列または日付または数値) を選択します。
メモ:
- 必要な出力フィールドに基づいて、データ型を選択します。 たとえば、出力を日/週/月の数として表示する場合は、出力データ型を数値として選択します。
- 関数とフィールドは、データ型の選択に基づいて異なる場合があります。
- 数値データタイプの場合、[EXPRESSIONのタイプ] ドロップダウン リストから [関数] または [EXPRESSION] として [EXPRESSIONのタイプ] を選択できます。
- 日付および日時フィールドの場合、カスタム会計期間を文字列データ型に追加できます。 次の関数を使用して、データ設計を構築します:
- カレンダー ラベル
- 会計四半期ラベル
- 会計年度ラベル
- 好みの関数を選択し、次に値やフィールドを入力します。
- [保存] をクリックし、数式フィールドを保存します。
- 保存をクリックして、変換データセットを保存します。
変換データセットで[プレビュー]をクリックすると、新しく作成された数式フィールドの記録をプレビューすることができます。
ケースフィールドを追加する
ケース EXPRESSIONフィールドを使うことにより、特定の一連の要件に基づいてデータを分類することができます。この数式関数を使用して、出力フィールドを作成することができます。この出力フィールドには、特定の一連の要件に合致する記録の値が含まれています。
データデザイナーの準備の詳細のケースフィールドは、バイオニックルールのケースフィールドとして機能します。ケースフィールドの作成方法の詳細については、ケース フィールド (近日公開予定) 記事を参照してください。
ケースフィールドを作成するには:
- 「ケースフィールドを追加」をクリックします。
- ラベル: [ラベル]テキストボックスに数式フィールド名を入力します。
- 必要なデータタイプ (数値/文字列/ブール) を選択します。ケース出力に表示されるオプションは、出力データタイプによって異なります。
メモ:[データタイプ]で[数値]を選択した場合、浮動小数点数については、出力を表示する必要がある小数点以下の桁数を選択します。 - ケース:ケースはクライテリアで構成されます。[+] をクリックすると、複数のクライテリアを追加できます。
- クライテリア。クライテリアには次の様々なフィールドがあります:
- フィールド: クライテリアを適用する必要があるフィールドを選択します。データセットに含まれるすべてのフィールドがここに表示されます。
- オペレーター:フィールドに適用するオペレータを選択します。選択したフィールドに基づいた演算子が表示されます。
- マッチング基準: このクライテリアが成功するために満たす必要がある合致基準を選択します。次のいずれかを選択することができます。
- 値:フィールド値と合致する必要がある値を入力します。
- フィールド: 最初のフィールドで選択されたフィールドの値と合致する値を持つフィールドを選択します。
- Advanced Logic: 複数のクライテリアがある場合は、それらのクライテリアの間に適用する論理演算子を選択します。デフォルトでは、ANDロジックが適用されます。
- Then: すべてのクライテリアが一致すると、このフィールドで指定されたアクションが実行されます。このフィールドで利用可能なオプションは、[出力データ タイプ] フィールドで選択した値によって異なります。
- Default: このフィールドはデフォルトのケースを表します。この場合のクライテリアはありません。アクションしかありません。すべてのケースが失敗した場合、このケースが実行されます。
- 保存をクリックして、ケース EXPRESSIONを保存します。
- 保存をクリックして、データセットを変換します。
ケース EXPRESSION実行の詳細:
- ケース EXPRESSIONの実行は、レコードの最初のケースの評価から始まります。レコードがこのケースのすべてのクライテリアを満たす場合、このケースに関連付けられたアクションが実行されます。このレコードのケース EXPRESSIONの実行はここで停止し、他のケースは評価されません。
- ただし、最初のケースが満たされていない場合、システムは同じレコードで2番目のケースを評価します。利用可能なケースのいずれもレコードによって満たされていない場合、デフォルトのケースが実行されます。
フィルター
変換のフィルターは、データセットの編集のフィルターとして機能します。詳細については、フィルターセクションを参照してください。
詳細と概要
変換の概要の詳細はデータセットの編集の詳細と詳細と概要と同じです。詳細については詳細と概要セクションを参照してください。
マージ
次の方法でデータセットをマージすることができます。
- マージするデータセットの[オプション]をクリックし、[マージ]をクリックして、必要なデータセットを選択します。(または)
- 最初のデータセットを2番目のデータセットにドラッグアンドドロップします。
データセットを結合すると、データセット名が[マージ]の新しいウィンドウが表示され、[詳細と概要]、[結合]、[フィールド]、および[フィルター]タブが表示されます。
結合
基本的な結合クローズは、2つ以上のテーブルの行をそれらの間の共通フィールドに基づいて結合するために使用されます。Gainsightでサポートされている結合には4つのタイプがあります。内部結合、左結合、右結合、および外部結合です。各結合タイプは、データデザイナーのマージタスクで使われると、わずかに異なるデータ セットが生成されます。詳細情報については、結合タイプ (近日公開予定) 記事をご参照ください。
- 内部結合: この結合は両方のデータセットから共通の記録を保持します。
- 左結合: この結合は、左のデータセットのすべての記録を保持します。
- 右結合: この結合は、右のデータセットのすべての記録を保持します。
- 外部結合: この結合は両方のデータセットの全ての記録を保持します。
2つのデータセットを結合するには:
- [結合]タブに移動します。
- 必要な結合タイプを選択します。
- 各データセットからフィールドを選択してクライテリアを設定します。例えば、最初のデータセットのカンパニー名は名前で、2番目のデータセットのカンパニー名はカンパニー名です。
- [+]をクリックして、複数フィールドマッピングを追加します。これは、記録のフィルタリングに役立ちます。
- [保存] をクリックします。
フィールド
フィールドタブから次のオプションを閲覧することができます:
- フィールドを検索:[フィールド検索]テキストボックスに、検索したいフィールド名を入力します。検索操作はデータセットで利用可能なフィールドで行われます。
- すべて選択:チェックボックスを選択/選択解除して、マージされたデータセットからフィールドを追加/削除します。 (または) 個々のフィールドのチェックボックスを選択/選択解除することも可能です。
- 表示名:デフォルトでは、[表示名]テキストボックスに[フィールド名]が表示されますが、必要に応じて変更することができます。表示名はデータセット/レポートに表示されます。
- 保存:[保存]をクリックして、マージされたデータセットに加えた変更を保存します。
フィルター
マージのフィルターは、データセットの編集のフィルターとして機能します。詳細については、フィルターセクションを参照してください。
詳細と概要
マージの概要の詳細はデータセットの編集の詳細と詳細と概要と同じです。詳細については詳細と概要セクションを参照してください。
統合
データデザイナーの統合
関数は、2つのデータセットを組み合わせて、類似したタイプのフィールドがすべて自動的に1つのデータセットに統合されるようにします。2つのデータセットに類似していない他のフィールドがある場合は、それらを選択して追加することができます。
ビジネスユースケース: 例えば、ヨーロッパおよび米国地域の顧客からのデータを持つ2つのオブジェクト (同様のフィールドを持つ) のデータを結合するとします。
メモ:
- 統合フィールドは、データタイプ、小数点などのマスターフィールドのプロパティを引継ぎます。
- 統合フィールド以外にも、データセットからフィールドを追加することが可能です。列にデータが入っていない場合は、Nullと見なされます。
- 出力データの重複フィールドを削除するかどうかを選択することができます。
統合関数を使用するには:
- 統合を適用するデータセットの[オプション]をクリックし、[統合]をクリックして、必要なデータセットを選択します。[統合]タブに移動します。
- 統合タイプを選択します。次のオプションから選択できます。
- 結合:出力データの重複を削除するためには、これを選択します。
- 全てを統合:出力データの重複を保持するためには、これを選択します。
- [マージするマップフィールド]セクションで、各データセットからフィールドを選択してマージクライテリアを設定します。
- 必要に応じて、[+]をクリックして、複数フィールドマッピングを追加します。これは、記録のフィルタリングに役立ちます。
- [フィールド]タブに移動して統合フィールドを表示し、(データセットから) マスターフィールドを選択し、フィールドを選択/選択解除してフィールドの表示名を変更します。.
メモ:必要に応じて、データセットから追加のフィールドを選択することも可能です。 - [保存] をクリックします。
ピボット
データセットでは、ピボットタスクは1つのテーブル列で使用可能なデータを一度に複数の列に変換します。ピボットタスクはテーブル列のすべてのデータ値に対して列を作成します。これにより、データ要約プロセスが強化され、データに対する洞察が改善します。
ピボット機能:ピボットは EXPRESSIONの1つの列の一意の値を出力の複数の列に変換することにより、テーブル値式を回転します。
ビジネスユースケースの例:カスタマーサクセスディレクターは、CSM毎にCTAタイプのパターンを見つけて、CTAタイプを最適化したいと考えています。
ピボット機能を使用するためには、[管理] > [データ デザイナー] > [データセットを開く] の順にに移動し、[オプション] をクリックして、[ピボット] をクリックします。
CTAタイプ名フィールドでピボットする方法の詳細については、、データデザイナーでピボットタスク記事を参照してください。
データセットの自動配置
[デザインの配置]オプションを使うと、1回のクリックで[準備]タブでデータセットを自動的に配置することができます。デザインに多数のデータセットがある場合は、次の図に示す様に、ズームイン、ズームアウト、パンなどのオプションを利用することができます。
データセットのプレビュー
データセットをプレビューするには、[目]のアイコン (または) [オプション]をクリックし、次に[データセットのプレビュー]をクリックします。プレビューでは、最大2,000件の記録を表示することができます。
マージと変換のプレビューでは、最初の2,000件の記録が表示されます。場合によっては、データセットが小さくなるか、行がなくなることがあります。
最大化: [プレビュー]タブの[最大化]アイコンをクリックして、サンプルデータを全画面表示することも可能です。
リフレッシュ: データセットを編集した場合は、[プレビュー]タブにある[更新]をクリックしてサンプルデータを更新します。
ソート操作:このオプションを使用すると、大規模なデータセットがある場合に全ての記録を並べ替えることが可能です。
(出力データセット)のプレビュー
出力データセットをプレビューするには:
デザインページの右上隅にある[プレビュー]をクリックします。 (または) デザインの出力/最後のデータセットに移動し、[目]のアイコンをクリックします。 (または) [オプション]をクリックし、次に[プレビュー]をクリックします。
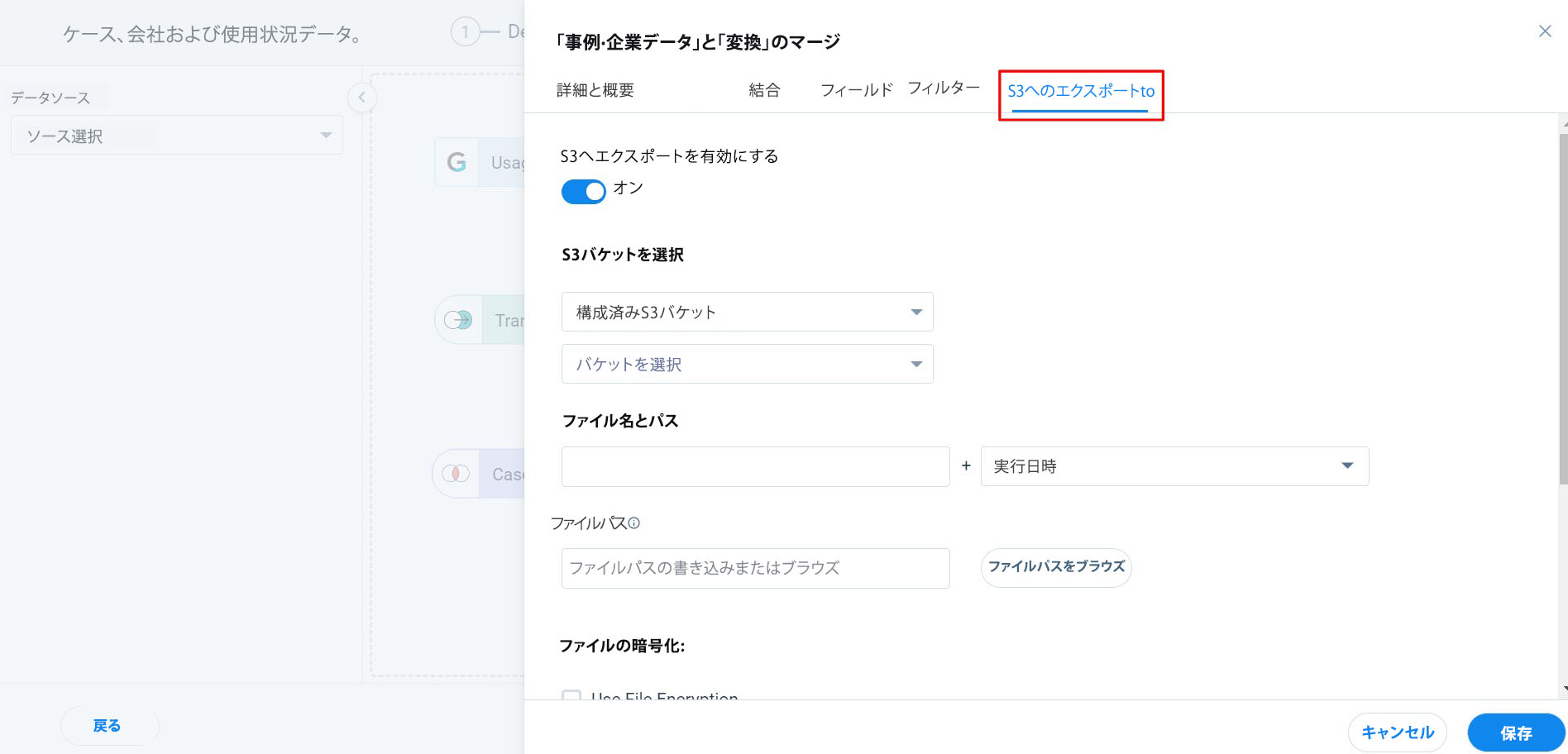
S3へのエクスポート
S3へのエクスポート機能を使用すると、出力データをデータセットレベルで[準備]タブからAmazon S3バケットに直接エクスポートすることができます。概要とデータデザイナーから S3 にデータをエクスポートする方法の詳細については、データデザイナーからS3にエクスポート記事を参照してください。
データセットをデザインテンプレートとして保存
データセットが作成されると、ユーザーはこのデザインをデザインテンプレートとして保存することができます。これは、バリエーションのある同様のデータセットを作成するためのベースデザインとして使用することができます。
データセットをデザインテンプレートとして保存
- [新規保存]をクリックします。[デザインテンプレートとして保存]ダイアログが表示されます。
- [デザインテンプレートとして保存]ダイアログから、次のいずれかのオプションを選択します:
- 新しいデザイン テンプレートを新規として保存します。
- 既存のテンプレートを更新する場合は、[既存の更新]を選択します。
- [テンプレートを保存]をクリックします。
デザインテンプレートの使用方法の詳細については、データデザイナーでのデザインテンプレート記事を参照してください。